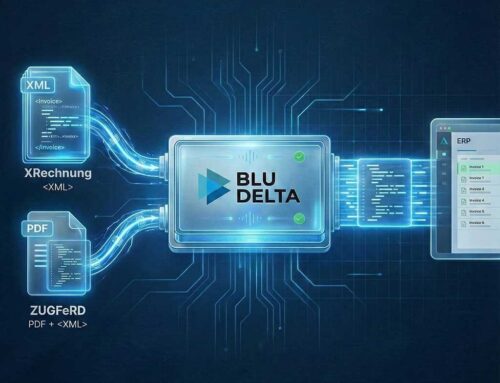
OCR technology – i.e. converting digital images and PDFs into usable (text) information – has been experiencing a silent, technological revolution since 2015. Artificial intelligence has brought new impetus to the previously static market. Especially young companies whose OCR products came onto the market after 2015 were able to develop their systems from scratch with AI and thus have a great qualitative advantage over the classic OCR solution approaches.


But even within the AI-focused OCR community, there are differences. Since 2015, new AI methods to improve OCR systems have been developed in research almost continuously. While in 2015 people were still working with classic machine learning models, today the technology leaders use NLP, deep learning and transformer architectures.
The advantages for the customers are immediate better results without effort and a system that actually learns and is not just a simplified template or template management.
This gives users better but also more diverse options for converting images into text and subsequently into structured information. But more variety also means being spoiled for choice.
The following guide therefore provides an overview of the differences between modern AI OCR systems and algorithm-based or template-based systems. Furthermore, this article explains specific points to consider when faced with the task of selecting a new OCR for a company. A link to the BLU DELTA OCR checklist as a basis for a Proof-of-Concept (PoC) or Request for Proposal (RFP) can be found in the last part of the article in addition to the download. Thus, we equip you with the knowledge you need to successfully select the right OCR for your use case.
But first things first - let's take a closer look at what an OCR does and how it works. This also gives rise to the first aspects that you have to pay attention to when making your selection.
What exactly is an OCR system?
An OCR (optical character recognition, optical character recognition or text recognition) converts an already digitized image with pure pixel information into text characters. Pixels that belong together and represent a known character are thus placed in a written and language context and translated into machine-readable characters (letters, numbers, etc.).
So, OCR is a technology that enables the conversion of scanned paper documents, PDF files or digital photos into editable documents for computers and software (such as Microsoft Word or financial accounting software).
For example, if you want to process an invoice, an order or a contract that someone sent you as an image-based email attachment, then the pixel information is not sufficient to be able to continue working directly with the information from these documents. The scanner only takes an image of the document and this consists of a collection of pixels with color information. The following technical steps must be taken to process the information from scanned documents, digital images or image PDFs:

- Conversion of pixels to character strings (letters and numbers)
- Conversion of letters to types: words, amounts, IDs, numbers, names, addresses,
- Conversion of the types into meaning: document type, document date, gross total amount, sender name, UID, IBAN, etc.)
OCR ≠ Semantics
From a technical point of view, an OCR only fulfills the first step (see also optical character recognition - Wikipedia)! In management floors and financial accounting departments, however, the OCR term (optical character recognition) has become established as an overall process (steps 1 to 3). The following article also helps to clarify the OCR term: Invoice capturing: OCR, iOCR and KI.
How does an OCR system work?
Let's see how an OCR software works. First, the OCR application analyzes the structure of the document. It divides a page into structural elements such as blocks of text, tables, and images. Then lines are formed, which are divided into words and finally into letters.

Once the individual letters have been identified, the program compares them to a series of sample images and calculates the probability of a match (see image character is 83% an "L" but only 16% an "I"). The OCR software then makes a decision for the most probable character and assigns it a standardized code (e.g. ISO8859-1).
An OCR system can also be configured for multiple languages. The more languages to be covered, the more difficult the task for the OCR and the recognition quality can decrease. Think, for example, of the distinction in German: "a" vs "ä", which does not exist in the English language.
In addition, algorithmic OCR text recognition often offers dictionary support for different languages. This allows the OCR to be optimized for a specific context (e.g. accounting).
Image quality is crucial for automation with OCR
Converting an image into a document only takes a few seconds. In a first step, you get a text and its meta information such as text size, font and position without manual effort.
I.e. after step 1 an “image” or “image PDF” is searchable, you can select the text and copy it. Thanks to his intelligence, a person can now process these characters (search, copy, etc.) and assign semantics with the help of his laptop. For example, this character string is the input date. In this case, the human takes on steps 2 and 3 – i.e. recognizing the semantic meaning.
But actually we want the machine to take over the automation of this mundane activity for humans. For automated human support, the machine must recognize the semantic meaning of the text itself. A high quality of the first step (technical OCR) is therefore a prerequisite for a good semantic evaluation and thus a high level of automation in the following business processes.
The characters, words and numbers as well as their meta information (font, size, position, etc.) form an important data source for algorithms and AI models based on them. Both modern AI approaches such as DeepOCR and older OCR approaches based on statistical models deliver the desired output here.
Algorithmic OCR vs. DeepOCR
This is a big topic and at this point we only want to go into the most important differences from the customer's point of view. In principle, an algorithmic OCR is a rigid software structure. Improvements are achieved by using a developer who makes the changes to the source code, tests it and provides the customers with a new release. A process that enables automated learning and automatic improvement of text recognition (step 1) is therefore excluded.
A DeepOCR learns from data. The developers implement the learning process and then the system can be trained using examples of numbers, letters and words. A trained DeepOCR can learn a lot more situations and makes fewer mistakes. In addition, a learning process can also be created for your own use case and trained accordingly. You can find more about this with a comparison of existing OCR and DeepOCR products in the following article: OCR and DeepOCR in comparison.
The disadvantage of DeepOCR can be the performance or the more expensive hardware. If you have an online application and therefore "real-time" results are required, then you need special hardware with special processors (so-called Graphical Processing Units, GPU) for your application or you simply use a cloud service.
As already mentioned, an OCR system determines the probability of how closely a character corresponds to a certain number or letter. An "8" quickly becomes a "6" or a "B" because this probability varies with image quality.
Blurry images, text with a colored background or simply poorly scanned documents can have a major impact on the quality. In our regular BLU DELTA benchmarks (quality measurement for AI systems), we see that the photo and scan quality is crucial for the subsequent processes.
In this area in particular, DeepOCR has achieved considerable success. In our measurements, DeepOCR systems had significant advantages (approx. 10-30% more accurate), depending on the manufacturer.
However, a “tipped” letter does not have to have a major impact. A prerequisite for this, however, is a forgiving recognition of the meaning of the words, which modern Natural Language Programming AI approaches (NLP) bring with them. More on that later in the article.
Up to 30% higher automation rate with AI
Due to poor scan and image quality, we see differences of up to 30% in the automation rates in document capture from our customers. These differences are also one of the reasons why recognition rates and automation rates vary from one company to the next. Therefore, we advise companies with larger volumes to predict the automation rate.
Digital photo and OCR
As a rule, images taken with mobile devices have the following problems:
- Shadows
- Uneven illumination
- Wrong perspective
- Additional areas outside the page borders
An OCR software can correct these problems to a certain degree. Nevertheless, digital photos represent the greatest challenge for automation due to the points mentioned above. So-called cam scanners or similar mobile OCR scanners and/or image optimizations can improve the quality accordingly in advance.
Scan and OCR
Professional scanners already offer a good basis for the automated processing and capture of documents. If possible, scan your documents in black and white (thus lossless compression is possible) and with at least 300dpi. Small fonts up to 9pt can still be recognized well.
PDF text and OCR
PDF text gives the best results. The actual OCR process is usually omitted here. The PDF document already contains the characters in digital form and the subsequent process "only" has to recognize the semantics. Documents in pure PDF text format achieve overall recognition rates of more than 90% with the BLU DELTA KI. If possible, you should therefore ensure that you receive unstructured or semi-structured documents as PDF text from your document sources.
However, PDF text documents are often enriched with images that contain text information. In this case, the advantage is put into perspective.
See also our article: Tips and tricks for better OCR results.
From text to meaning
Modern NLP (Natural Language Processing) approaches can "iron out" such errors. With NLP, certain words are classified and can thus be assigned to certain data types. For example, it is recognized that "12.3.2019" is just as much a date as "3. March 19". Errors in words such as delivary note vs. delivery note can also be corrected automatically and previous OCR errors corrected.
An artificial intelligence (e.g. our BLU DELTA KI invoice entry) uses the results of the OCR to automatically and without further manual effort extract usable information for the subsequent processes (e.g. accounts payable). The customer not only receives character strings, words and numbers, but also their meaning - this is often referred to as an intelligent OCR (or iOCR).
Especially in the field of (accounts payable) accounting, the term OCR is often equated with the recording of information from invoices. This means that the OCR contains a component for text recognition (OCR) and models (AI or algorithmic) based on it that can capture the semantic relationships.
Before 2015: OCR Templates
A template-based approach means that the customer has tools at hand to create a template for each supplier. Using this template, the system can then "intelligently" identify an incoming invoice layout, select the correct template and then try to find the correct fields using this template.
To better illustrate it, one can also imagine that a clerk places a slide over an incoming invoice from a supplier, marks the position of the fields to be read with a marker pen and then files it under the supplier's name. If another invoice from this supplier is received, the corresponding foil is taken again and placed over the new invoice so that the fields to be read out can be read out faster and as automatically as possible.
Unfortunately, the layouts change by shifting the position when inserting longer text, several lines, inserted notes, notes, new logos, etc. Despite "smart" templates, this system cannot always cover all cases and there is still manual effort.
Companies that have many suppliers with many different invoice layouts have to invest additionally in a self-made, extensive library of templates that also needs to be maintained.
In order to be able to cushion these changes as well as possible, the strengths of such systems do not always lie in the recognition of the information but in the comparison with existing information (master data and transaction data of a company). However, this data (e.g. supplier database or orders from the ERP, etc.) is not always available, incomplete or of poor quality or does not match the information provided by the supplier.
Item data of an invoice, for example, can often no longer be handled with a reasonable amount of effort if there are only a few suppliers.
2015: OCR begins to understand documents

In 2015, AI entered the OCR field. The technology trend away from “memorizing documents” (templates) to “understanding documents” (AI) began. The AI does not memorize the invoice for each supplier, but derives (similar to humans) general patterns for recognition. Humans recognize a date by the way it is written, where it is written, and by its visual characteristics. And humans can do this because they have seen many examples of date formats before. Artificial intelligence also learns from examples. It is therefore possible that only one OCR AI can be trained for many customers (shared intelligence). All customers contribute by example to make AI better for all customers.
Current AI OCR systems can also understand individual sentences. Meanings across several sentences is (still) a challenge for the common AI and NLP models.
Learning new patterns can be seamlessly integrated into the process and can go unnoticed by clerks. Templates or templates per supplier are no longer necessary.
Template-based or Deep Learning?
Based on the properties of the systems, one can basically say that wherever there are rigid layouts (e.g. forms) or similar documents that only have a small variance in terms of layouts, template-based systems work well and reliably and have no disadvantage compared to AI .
Where the layouts are not very standardized and therefore differ more in type and form, deep learning and/or artificial intelligence has clear advantages. All of this relates to semi-structured documents. For prose or emails, you should definitely look at AI-based systems.
DeepLearning models can also be pre-trained. This means that the system has already been brought to a very good level using sample data from the AI manufacturer. This applies to certain document types that are common on the market (orders, invoices, delivery notes, etc.). These pre-trained models can be seamlessly embedded in your own systems after a very short integration time (the system does not have to be trained). If the manufacturer also uses a shared intelligence concept (all companies train a system together), you get a very high quality.
In general, one can say that a pre-trained AI OCR system based on shared intelligence for semi-structured documents e.g. invoices, delivery notes, etc. immediately delivers better results than a well-maintained template-based system. Only the AI starts to get even better at this point.
For individual documents, AI has the disadvantage that you need examples that the AI can learn from. If these examples are not available, one must resort to synthetic data generation or manual creation of examples (annotating existing documents).
Select the correct OCR
The most important step in choosing the right OCR is to evaluate your own problem in order to then select the best solution for the problem. The following criteria (also as OCR) should help you to assess your own situation correctly so that you can then select the appropriate OCR.

OCR Guide - Checklist
- document type
- form-like
- Semi-structured
- off the shelf solution:
- invoice
- delivery note
- order
- Other:
- prose
- Input channels: photo, scan, e-mail, online portals, fax
- Handwriting recognition required
- Image formats: jpg, png, pdf, tiff
- language
- What is the distribution of the languages and is there one language that dominates
- region
- Do the documents also have an indirect dependency on a region or state (e.g. certain rules on VAT)
- What is the distribution of the region or is there a region that dominates
- number of documents
- Are changes planned in the future - e.g. through merge & acquisition activities
- Is it expected that the volume increases, decreases
- New regions/languages
- Average number of pages per document
- Expected layout variety:
- Each sender has its own format
- number of transmitters
- Rigid, form-based format
- Each sender has its own format
- Required information from the documents
- Let the specialist department mark the required fields for 3-10 documents
- Do the fields have a restricted range of values
- Is there a reference for these fields in your master or transaction data
- Examples available: Have you previously entered this data manually?
- Separation of scan batches necessary
- Document test set
It is important to define a representative test set of documents that you can use to measure or check the quality of the OCR. The OCR system should never have processed this test set or, in the case of an AI OCR, should not have been trained with these documents.
- Size test set:
In order for it to be meaningful, it must have a minimum size in addition to being random. At least 300 would be recommended – the more the better. From 1000 documents one has a good reliability.
- Integration:
- In which target system should the data of the OCR output be integrated?
- Are there simple generic interfaces that support hassle-free integration?
- Are interfaces already available for your target system?
- Which master data from your systems can be made available
- Type of operation:
- cloud
- On-premise:
- Is hardware with GPU available?
- Privacy Security of data
- GDPR: Do documents contain personal data
- Do documents contain data of a special category (according to GDPR)
- Is your industry subject to special confidentiality obligations (banks, insurers, tax consultants, etc.)
- Certifications required (e.g. ISO27001)
- OCR target defined
- Detection rates and/or automation rates for your use case
In your checklist, make a distinction above all between requirements that you absolutely need for added value vs. requirements that are "nice-to-have".
If you heed this checklist or OCR guide, then you have taken the basis and at the same time the most important step for a successful OCR system selection.
Key criteria for the right OCR
Of course, each OCR RFP or OCR evaluation has individual requirements. The following points summarize the most important criteria from our experience, which are essential in every OCR project (especially with AI OCR solutions):
Rigid document structure or free form: As already discussed: The more freedom the authors of the documents have in the design, the more AI and deep learning
Image quality or large proportion of PDF/text: The worse the image quality, the more likely it is DeepOCR
Complexity of data fields: Which data do you have to extract and how complex or how much free form do they contain? (e.g. simple table vs. complex table)
Extraction vs. master data: what needs to be extracted vs. what can be recorded indirectly via mapping from the structured master data or transaction data
Data protection: Usually decides on on-premise vs. cloud
Sample data available for AI training: In the case of individual projects or documents, a good database simplifies the task considerably.
If you have any questions about the OCR guide or the checklist, please contact us or use the online appointment calendar.
BLU DELTA is a product for the automated capture of financial documents. Partners, but also finance departments, accounts payable accountants and tax advisors of our customers can use BLU DELTA to immediately relieve their employees of the time-consuming and mostly manual capture of documents by using BLU DELTA AI and Cloud.
BLU DELTA is an artificial intelligence from Blumatix Intelligence GmbH.