“In the good old days” in companies and public authorities, incoming documents were examined by the incoming mail department, administration, or secretary and then forwarded accordingly. These business documents ranged from invoices, receipts, tax assessments, etc. to contracts. Each of these documents had to be forwarded to the responsible department. Finally, they were manually processed and properly filed in a large archive.


Digitization is the prerequisite for document classification
Many companies have digitized their systems in the last ten years, and the volume of incoming paper documents is decreasing year by year. Many organizations have already switched to digital mailrooms, file management systems, and archives and receive most of their documents by email. Some work with large scanners to digitize the remaining part of the process.
However, in many companies, these documents were often only digitized. Classification of the document type was not carried out and moved to the “next project phase”. The creation of a searchable text layer for each document was not always performed either – leave aside the actual most valuable aspect: extracting information from the documents.
The receipt and conversion of documents into a digital format (document capturing) is always only a first step towards reducing sources of error and increasing operational efficiency. The classification, sorting, and forwarding of documents to the correct department and ensuring that the documents are available in searchable text are valuable next steps. With intelligent OCR & artificial intelligence that begins to understand documents, these steps can be fully automated and easily integrated as part of the document intake and processing.
In this blog, we will discuss how latest AI can be used to automatically classify documents.
Transformer AI Makes Classification Easy
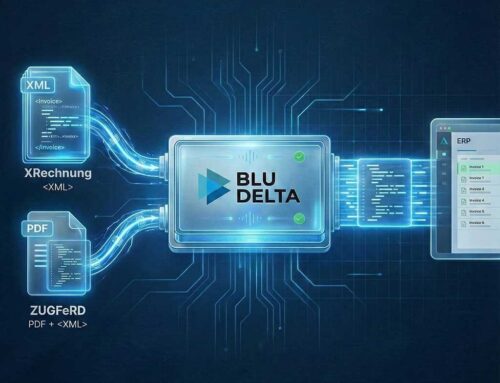
Pre-trained models based on Transformer architectures, such as those used by ChatGPT, help with automated classification. For standard documents such as invoices, receipts, delivery notes, transport documents, export accompanying documents, payment advice, tax receipts, etc., our BLU DELTA Classifier, for example, can immediately identify the document type based on a screenshot, image, or PDF - without any additional training!
The AI model analyzes the text in the image, the structure down to the individual pixels, and based on this information, assigns the document to a general document type. The artificial intelligence has already learned these types in several languages from many previous training epochs and examples and can apply them immediately to new documents.

With automated document classification, an accuracy of more than 99% can be achieved, with a single sorting process automatically running 24/7. The human error rate in this area is between 2-7%. These errors can also lead to the triggering of incorrect processes, and companies often have no routine for these cases. Errors in this area are often associated with increased costs.
Document classification: ready2use or customized training?
There are generally applicable business documents (e.g. invoices, delivery notes, vehicle registrations, etc.), industry-specific documents (e.g., transport documents in logistics, etc.), and customer-specific documents.
The BLU DELTA Classyfier offers different approaches here. There are pre-trained models that are immediately applicable for generally applicable documents and do not require any training for a specific use case.
Weiters gibt es auch für spezielle Branchen (Logistik, Bau, etc.) bereits vortrainierte Modelle. Bei Dokumentenklassen, die nur in dem Firmenkontext bekannt sind, benötigt man dann in den meisten Fällen auch ein Training.
There are also pre-trained models for specific industries (logistics, construction, etc.). For document classes that are only known in the company context, training is required in most cases.
Combined with the BLU DELTA Capture API, many other use cases can be covered for classification:
Document classification is a key to automation. Nowadays, many standard documents can be classified immediately without training. If this is not sufficient, modern AI systems can be improved fully automatically.
BLU DELTA is a product for the automated capture of financial documents. Partners, but also finance departments, accounts payable accountants and tax advisors of our customers can use BLU DELTA to immediately relieve their employees of the time-consuming and mostly manual capture of documents by using BLU DELTA AI and Cloud.
BLU DELTA is an artificial intelligence from Blumatix Intelligence GmbH.

Author: Christian Weiler is the former General Manager of a global IT company based in Seattle/US. Since 2016, Christian Weiler has been increasingly active in the field of artificial intelligence in a variety of roles and has been part of the management team of Blumatix Intelligence GmbH since 2018.
Contact: c.weiler@blumatix.com