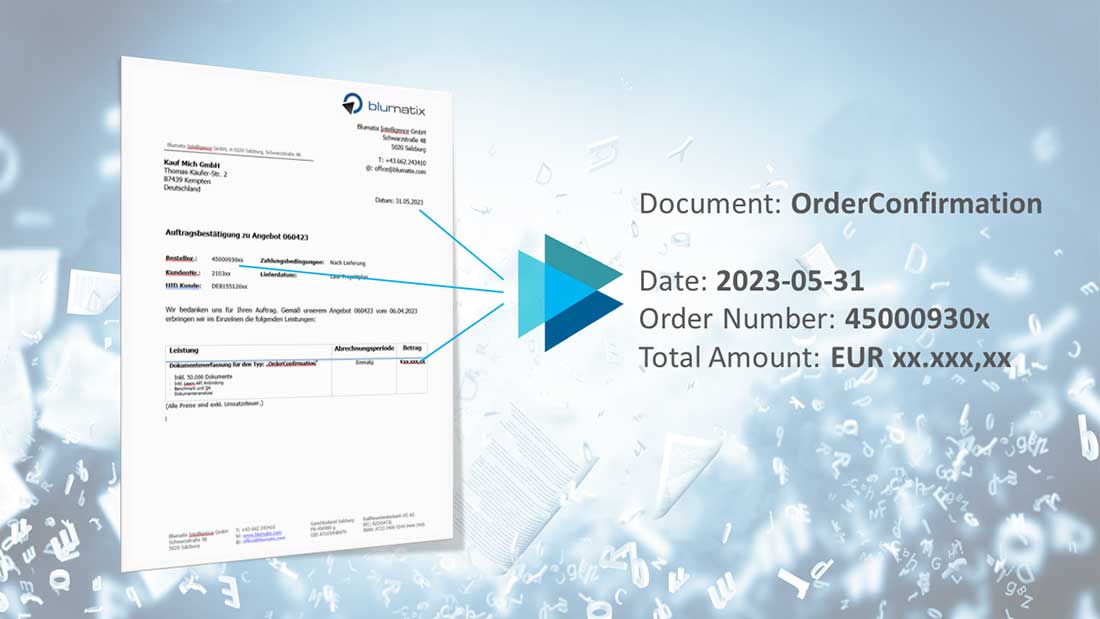
In nahezu jedem Bereich des alltäglichen Privat- und Berufslebens hat die Digitalisierung in den letzten Jahren rasant an Bedeutung gewonnen, so auch beim Sichern, Weiterleiten und Abrufen der verschiedensten Dokumente. Und genau dabei kommen wir ins Spiel: Wir unterstützen Sie bei der digitalen Dokumentenerfassung, damit Sie Informationen aus unterschiedlichen Quellen schnell und präzise extrahieren und für die weitere Verarbeitung bereitstellen können. Denn in einer Zeit, in der die Menge an Geschäftsdokumenten exponentiell wächst, sind traditionelle Methoden, mit denen man Dokumente erfassen kann, oft nicht mehr ausreichend – auf jeden Fall deutlich weniger effizient.
Allerdings stehen die meisten Unternehmen vor der Herausforderung, große Mengen an Daten zu verarbeiten und dabei Fehler zu minimieren und die Effizienz zu maximieren. Und genau da setzen wir mit unserer innovativen Lösung an: BLU DELTA nutzt fortschrittliche KI-Technologie und revolutioniert die Art und Weise, wie Sie die verschiedensten Dokumente erfassen, digitalisieren und daraufhin sämtliche Daten extrahieren können. Mithilfe von modernen Algorithmen und lernenden Systemen heben wir die Genauigkeit und Geschwindigkeit der Dokumentenverarbeitung auf ein neues Niveau.
Dadurch wird die Dokumentenerfassung und -verarbeitung nicht nur schneller und genauer, sondern auch zukunftssicher und anpassbar an die sich ständig verändernden Anforderungen moderner Unternehmen.
Inhaltsverzeichnis
- Grundlagen der Dokumentenerfassung
- Wir stellen unsere KI-Technologie zur Erfassung von Dokumenten vor
- Varianten der Dokumentenerfassung mit BLU DELTA
- Nahtlose Integration und kontinuierliche Verbesserung der Digitalisierung von Dokumenten
- Zukunft der Dokumentenerfassung – ständige Weiterentwicklung und Innovation
- Schlussfolgerung / Fazit
- FAQ: Häufig gestellte Fragen zu Dokumentenerfassung mit unserer Software
- Beleg- und Dokumentenerfassung
Grundlagen der Dokumentenerfassung
Dokumentenerfassung bezeichnet den Prozess, bei dem Informationen aus physischen oder digitalen Dokumenten extrahiert und in ein elektronisches Format überführt werden. Dies kann durch manuelle Dateneingabe, durch Scannen und durch die Nutzung von Technologien wie Optical Character Recognition (OCR) erfolgen. Die erfassten Daten können anschließend in Datenbanken gespeichert, analysiert oder für verschiedene geschäftliche Zwecke verwendet werden.
In Unternehmen spielt das Erfassen von Dokumenten eine entscheidende Rolle, da sie die Grundlage für zahlreiche Geschäftsprozesse bildet. Von der Rechnungsverarbeitung über das Vertragsmanagement bis hin zur Kundenkommunikation – die Effizienz dieser Prozesse hängt maßgeblich von der Qualität und Geschwindigkeit der Dokumentenerfassung ab. Fehlerhafte oder langsame Datenerfassung kann zu Verzögerungen, zusätzlichen Kosten und sogar rechtlichen Problemen führen. Daher ist es unerlässlich, dass Unternehmen auf präzise und zuverlässige Methoden der Dokumentenerfassung setzen.
Traditionelle Methoden der Dokumentenerfassung
Traditionelle Methoden, mit denen man Dokumente erfassen und digitalisieren kann, umfassen die manuelle Dateneingabe und den Einsatz von Scannern in Kombination mit OCR-Technologie (Was ist OCR?).
- Manuelle Dateneingabe: Bei der manuellen Dateneingabe werden Informationen von Mitarbeitern direkt aus Dokumenten in elektronische Systeme übertragen. Dies ist oft zeitaufwendig und fehleranfällig, insbesondere bei großen Datenmengen oder komplexen Dokumenten.
- Scanner und OCR: Eine Weiterentwicklung der manuellen Eingabe ist die Verwendung von Scannern in Verbindung mit einer OCR-Software, die gedruckten Text in maschinenlesbaren Text umwandeln kann. Diese Methode ist schneller als die manuelle Eingabe und reduziert das Risiko von Eingabefehlern, allerdings ist sie bei der Erkennung komplexer oder schlecht lesbarer Dokumente begrenzt.
Herausforderungen der traditionellen Methoden
Trotz der Fortschritte, die traditionelle Methoden wie OCR gebracht haben, gibt es immer noch erhebliche Herausforderungen bei den Methoden der Dokumentenerfassung ohne KI:
- Zeitaufwand und Fehleranfälligkeit: Manuelle Prozesse sind zeitintensiv und anfällig für menschliche Fehler. Selbst kleine Ungenauigkeiten können zu erheblichen Problemen führen, insbesondere wenn die Daten in kritischen Geschäftsprozessen verwendet werden.
- Begrenzte Flexibilität bei der Verarbeitung unterschiedlicher Dokumententypen: Traditionelle Systeme stoßen oft an ihre Grenzen, wenn es darum geht, eine Vielzahl unterschiedlicher Dokumententypen zu verarbeiten. OCR-Systeme sind beispielsweise auf klar strukturierten Text angewiesen und können bei komplexen oder schlecht lesbaren Dokumenten scheitern. Auch die Dokumentenklassifizierung fällt hier schwer, was bei einer KI-gestützten Lösung wie der von BLU DELTA zuverlässig möglich ist.
Wir stellen unsere KI-Technologie zur Erfassung von Dokumenten vor

Mit unserer Architektur gelingt es, jedes Dokument zu digitalisieren
Wie bereits im Ansatz erwähnt, setzt BLU DELTA auf eine fortschrittliche KI-Technologie, die speziell für die (automatisierte) Dokumentenerfassung entwickelt wurde. Im Gegensatz zu herkömmlichen Methoden nutzt BLU DELTA spezialisierte Algorithmen, die in der Lage sind, komplexe Muster in Dokumenten zu erkennen und die relevante Datenextraktion zu beschleunigen. Die Architektur von BLU DELTA ist darauf ausgelegt, sich kontinuierlich zu verbessern, indem sie aus neuen Daten lernt und ihre Erkennungsfähigkeiten ständig optimiert. Die Software kombiniert maschinelles Lernen, Deep Learning, Natural Language Processing (NLP) und Large Language Models, sodass BLU DELTA in der Lage ist, selbst die anspruchsvollsten Dokumentenformate zu verarbeiten. Deutlich vereinfacht gesagt handelt es sich um eine innovative, moderne Steigerung eines OCR-Systems für Rechnungen, Verträge und viele, viele weitere Dokumente.
Und dennoch ist die Lösung für die intelligente Dokumentenerfassung dabei flexibel genug, um sich an unterschiedliche Branchenanforderungen anzupassen. Gleichzeitig gewährleisten wir natürlich die nötige Stabilität, um jederzeit eine hohe Erkennungsgenauigkeit sicherzustellen.
Diese Vorteile bietet Ihnen
die BLU-DELTA-Lösung
BLU DELTA bietet zahlreiche Vorteile gegenüber traditionellen Methoden der Dokumentenerfassung:
- Hohe Erkennungsgenauigkeit und Effizienz: Dank der fortschrittlichen Algorithmen und der kontinuierlichen Verbesserung der KI erreicht BLU DELTA eine außergewöhnlich hohe Erkennungsgenauigkeit. Dies reduziert die Notwendigkeit manueller Überprüfungen und Korrekturen und steigert die Effizienz erheblich.
- Flexibilität und Anpassungsfähigkeit der KI: Unsere Software ist in der Lage, sich an unterschiedliche Dokumententypen und Branchenanforderungen anzupassen. Die KI lernt kontinuierlich aus neuen Daten und verbessert ihre Erkennungsfähigkeiten, sodass sie stets auf dem neuesten Stand der Technik ist.
Vom Einzelposten-Erfassen mit OCR bis hin zur LLM-Dokumentenerfassung heben wir die Digitalisierung und Verarbeitung von Dokumenten bzw. deren Inhalte auf ein neues Level.
Varianten der Dokumentenerfassung mit BLU DELTA
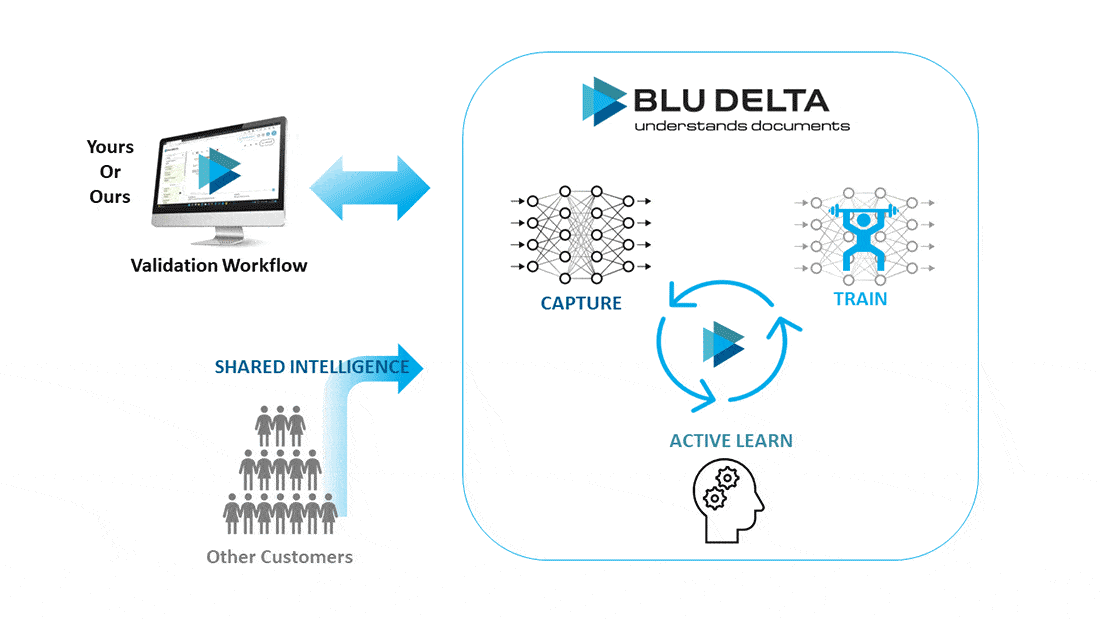
Sofortige Dokumentenerfassung für bekannte Dokumententypen
BLU DELTA ist eine sofort einsatzfähige hochmoderne Lösung zur Dokumentenerfassung für Unternehmen, deren Dokumententypen bereits in der Datenbank vorhanden sind.
- Nutzung der Shared-Intelligence-Methode: Diese Methode nutzt das Wissen, das aus einer Vielzahl von Dokumenten unterschiedlicher Kunden gesammelt wurde, um die Erkennungsgenauigkeit zu maximieren.
- Schnelle Einrichtung und sofortige Einsatzbereitschaft: Nach einer kurzen Einrichtung kann unsere KI-Lösung sofort genutzt werden. Dies ermöglicht es Unternehmen, ohne lange Wartezeiten oder umfangreiche Schulungen von den Vorteilen der KI-gestützten Dokumentenerfassung zu profitieren.
- Benchmark-Tests für Erkennungsraten: Um die Effizienz der Dokumentenerfassung zu überprüfen, bietet BLU DELTA Benchmark-Tests an. Diese liefern präzise Daten über die Erkennungsraten und helfen Unternehmen, den Nutzen der Lösung besser einschätzen zu können.
Dokumentenerfassung für Spezialfälle mit vorhandenen Trainingsdaten
Nicht alle Dokumententypen sind standardisiert, und einige Unternehmen haben sehr spezifische Anforderungen an die Dokumentenerfassung. Für diese Spezialfälle bietet BLU DELTA die Möglichkeit, die KI mit vorhandenen Trainingsdaten anzupassen.
- Anpassung und Training spezifischer Dokumententypen: Unternehmen können ihre eigenen Dokumententypen hochladen und BLU DELTA darauf trainieren. Dadurch wird sichergestellt, dass auch ungewöhnliche oder speziell formatierte Dokumente korrekt erkannt und verarbeitet werden.
- Upload von Beispieldaten über die Learn API: Über die Learn API können Unternehmen ihre Beispieldaten hochladen, die dann zur Verbesserung der KI verwendet werden. Dies ermöglicht eine schnelle und effiziente Anpassung an spezifische Anforderungen.
- Optimierung der Erkennungsqualität durch Experten: BLU DELTA bietet zudem Unterstützung durch Experten, die die Trainingsdaten analysieren und die Erkennungsqualität weiter optimieren. So wird eine maximale Präzision erreicht.
Dokumentenerfassung für unbekannte Dokumententypen ohne Trainingsdaten
Für den Fall, dass Unternehmen keine Trainingsdaten für ihre spezifischen Dokumententypen zur Verfügung haben, bietet BLU DELTA umfassende Unterstützung bei der Erstellung und Annotation dieser Daten.
- Unterstützung bei der Erstellung und Annotation von Trainingsdaten: BLU DELTA hilft Unternehmen dabei, die notwendigen Trainingsdaten zu erstellen und präzise zu annotieren. Dies ist besonders wichtig, um eine hohe Erkennungsgenauigkeit zu gewährleisten.
- Sicherstellung hoher Erkennungsraten durch präzise Datenannotation: Durch die präzise Annotation der Daten wird sichergestellt, dass die KI während des Trainings die richtigen Muster lernt. Dies führt zu deutlich besseren Erkennungsraten und einer zuverlässigeren Dokumentenverarbeitung.
Nahtlose Integration und kontinuierliche Verbesserung der Digitalisierung von Dokumenten

Integration in bestehende Workflows problemlos möglich
Eine der größten Herausforderungen bei der Einführung neuer Technologien ist die Integration in bestehende Systeme und Workflows. BLU DELTA wurde jedoch so entwickelt, dass es sich nahtlos in die vorhandenen Geschäftsprozesse einfügt.
- Einfache Einbindung: Unsere KI zur Dokumentenerfassung kann problemlos in bestehende Systeme integriert werden, ohne dass umfangreiche Anpassungen oder teure Implementierungsprojekte erforderlich sind. Dies minimiert den Aufwand und die Risiken bei der Einführung.
- Nutzung automatischer Korrekturen zur Verbesserung der Erkennung: BLU DELTA nutzt ein lernendes System, das automatisch aus Korrekturen lernt, die im Laufe der Zeit vorgenommen werden. Diese Korrekturen werden als neue Trainingsdaten verwendet, um die Erkennungsgenauigkeit kontinuierlich zu verbessern.
Qualitätsbeurteilung und Optimierung
Eine präzise Dokumentenerfassung erfordert zuverlässige Testdaten und eine kontinuierliche Optimierung.
- Bedeutung verlässlicher Testdaten: Die Qualität der Testdaten ist entscheidend für die Beurteilung der Effizienz und Genauigkeit der Dokumentenerfassung. Wir stehen Ihnen mit unserem Know-how bei der Erstellung und Nutzung hochwertiger Testdaten gerne zur Seite.
- Beratung für präzise Erkennungsraten und Effizienzsteigerung: Unternehmen, die die Effizienz ihrer Dokumentenerfassung maximieren möchten, können von der Expertise von BLU DELTA profitieren. Durch gezielte Beratung und Unterstützung bei der Optimierung können erhebliche Verbesserungen in der Genauigkeit und Effizienz erzielt werden.
Zukunft der Dokumentenerfassung – ständige Weiterentwicklung und Innovation

Die Zukunft der Dokumentenerfassung liegt in der kontinuierlichen Weiterentwicklung und Innovation der Technologien.
- Potenzielle Neuerungen und deren Auswirkungen: BLU DELTA könnte auf den Einsatz von multimodalen Large Language Models (LLMs) setzen, die sowohl Bild- als auch Textdaten gleichzeitig verarbeiten können. Diese Technologie eröffnet völlig neue Möglichkeiten in der Dokumentenerfassung und ermöglicht eine noch präzisere und effizientere Datenverarbeitung.
- Verwendung von multimodalen Large-Language-Modellen: Der Einsatz dieser Modelle ermöglicht es, komplexe Zusammenhänge zwischen Text und Bild in Dokumenten besser zu verstehen und zu analysieren. Dies ist besonders nützlich bei der Verarbeitung von Dokumenten, die sowohl Text- als auch Bildinformationen enthalten wie beispielsweise Rechnungen, technische Zeichnungen oder Verträge.
- Agentensysteme basierend auf LLM: Agentensysteme bestehen aus autonomen Einheiten, bekannt als Agenten, die in einer digitalen Umgebung operative Aufgaben erfüllen. Ein Agent kann Informationen sammeln, Entscheidungen treffen und auf seine Umgebung reagieren, ohne direkte menschliche Anleitung. Jeder Agent entspricht dabei einem LLM-Spezialisten, welcher konkrete Aufgaben übernimmt. Damit können in Kombination mit der Dokumentenerfassung weitere wichtige Prozessschritte (Teilschritte eines Workflows) unter Berücksichtigung von Unternehmensdaten (z. B. Stammdaten) automatisiert werden.
- Vision für die zukünftige Rolle der Dokumentenerfassung: Die Integration von LLMs und anderen fortschrittlichen Technologien in die Dokumentenerfassung wird die Rolle dieser Prozesse in Unternehmen grundlegend verändern. Zukünftig könnten Dokumentenerfassungsprozesse vollständig automatisiert und nahezu fehlerfrei ablaufen, was die Effizienz weiter steigern und die Kosten erheblich senken würde.
Schlussfolgerung / Fazit
Die Dokumentenerfassung ist ein unverzichtbarer Bestandteil moderner Geschäftsprozesse. Mit der fortschrittlichen KI-Technologie von BLU DELTA können Unternehmen diese Prozesse erheblich verbessern. Die Lösung bietet nicht nur eine hohe Erkennungsgenauigkeit und Effizienz, sondern ist auch flexibel und anpassbar an unterschiedliche Anforderungen. Durch die Integration von BLU DELTA in bestehende Workflows können Unternehmen von einer kontinuierlichen Verbesserung der Erkennungsgenauigkeit profitieren und sich gleichzeitig auf zukünftige Herausforderungen vorbereiten.
BLU DELTA setzt neue Maßstäbe und geht weit darüber hinaus, ein Dokument bloß zu digitalisieren. Wir bieten eine zukunftssichere Lösung, die den wachsenden Anforderungen moderner Unternehmen gerecht wird.
FAQ: Häufig gestellte Fragen zu Dokumentenerfassung mit unserer Software
Aus unserem Blog

BLU DELTA KI Lernbeschleuniger: Bounding Box
Die BLU DELTA KI lernt anhand von Trainingsdaten. In diesem Artikel erfahren Sie, wie dieser Prozess funktioniert und warum die Positionsinformation der Trainingsdaten, auch [...]

Datenerfassung beliebiger Dokumente in 4 Schritten
Die digitale Datenerfassung ist heutzutage dank künstlicher Intelligenz und Deep Learning ein müheloser Prozess geworden. In diesem Artikel zeigen wir Ihnen, wie Sie mithilfe der [...]

Datenextraktion erklärt – und automatisiert!
Die Datenextraktion, also das Erfassen von essenziellen Informationen aus un- oder semistrukturierten Dokumenten, stellt nach wie vor eines der größten Hindernisse in der Automatisierung [...]
Große Sprachmodelle (LLM): Vor- und Nachteile bei der Dokumentenerfassung
Dokumentenerfassung bezieht sich auf den Prozess, unstrukturierte Daten in ein normiertes, strukturiertes Format umzuwandeln. Im Wesentlichen entspricht dies einer Zusammenfassung eines Dokuments mit den [...]

Automatisierung von Prozessen am Beispiel KI für die Dokumentenerfassung
Das Webinar richtet sich speziell an Entscheider, Leader und Projektleiter. Basierend auf 8(+) Jahren KI Erfahrung wird Martin Loiperdinger (Blumatix CEO) darauf eingehen, worauf [...]
OCR: Leitfaden und Checkliste (2022)
Die OCR-Technologie – also digitale Bilder und PDFs in verwertbare (Text-)Informationen umzuwandeln - erfährt seit 2015 eine stille, technologische Revolution. Künstliche Intelligenz hat neuen [...]

Datenerfassung automatisieren mit KI: „same same but different“
Bei semistrukturierten Informationen und Dokumenten (wie z.B. Lieferscheine, Bestellungen, Rechnungen, Ausfuhrbegleitdokumente, Schadensfall Dokumentation, Gutachten, etc.) gilt die alte Weisheit: „same same but different“. Dies [...]