Dokumentenerfassung bezieht sich auf den Prozess, unstrukturierte Daten in ein normiertes, strukturiertes Format umzuwandeln. Im Wesentlichen entspricht dies einer Zusammenfassung eines Dokuments mit den essenziellen Informationen in einem vordefinierten strukturierten und einheitlichen Format.
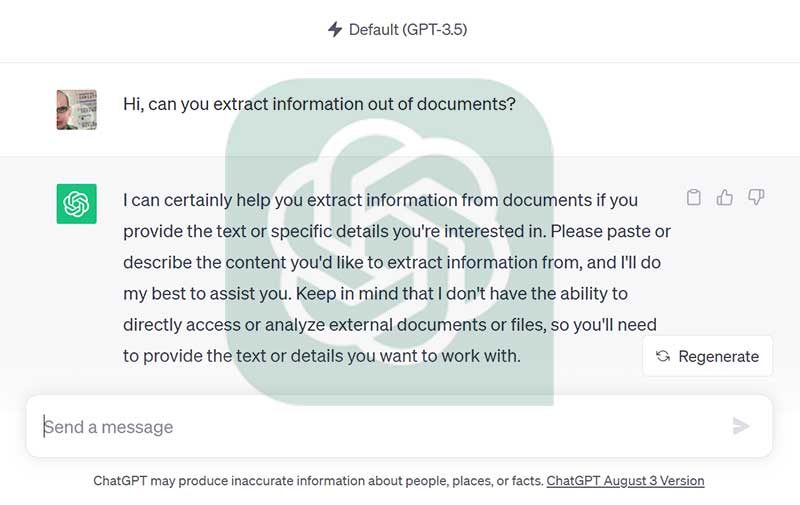

Auf den ersten Blick scheint dies eine ideale Aufgabe für ein Sprachmodell wie ChatGPT oder andere vortrainierte LLMs zu sein. (Für einen umfassenden Überblick über LLMs, einschließlich Details über Inferenz, Training, Anwendungen und Herausforderungen kann folgendes Research Paper hilfreich sein).
Sie - lieber Leser - haben vielleicht ChatGPT oder Llama, Falcon, etc. bereits für die Zusammenfassung eines Dokuments genutzt. Aber kann diese auch in einen Backoffice Prozess in einem Unternehmen integriert werden? Insbesondere in Bereichen, in denen konsistente und vertrauenswürdige Resultate von größter Bedeutung sind?
Betrachten wir den Einsatz von LLMs für die Dokumentenerfassung in Backoffice-Prozessen genauer und suchen nach Wegen, ihre Zuverlässigkeit sicherzustellen.
LLMs sind für menschenähnliche Texte konzipiert
LLMs sind darauf ausgelegt, menschenähnliche Spracheingaben zu verstehen und menschenähnliche Textausgaben zu produzieren. Für die Dokumentenerfassung bedeutet dies, dass wir vor dem Einsatz von LLMs unsere Bilder oder PDF-ähnlichen Dateien in Text umwandeln müssen. Das sogenannte OCR (siehe auch in unserem Artikel: "Was ist OCR?") und die damit verbundene Fehlerquelle bei schlechter Bild- oder Dokumentqualität bleibt uns also nicht erspart.
Wie steht es um das Layout?
Menschen kommunizieren Informationen nicht nur durch Prosa. Wir verwenden Absätze, Tabellen, Ausrichtungen und mehr, um Informationen effizient zu vermitteln. Das Layout ist damit ein Träger von Bedeutung. LLMs können keine 2-dimensionalen Informationen verarbeiten. Sie prozessieren reinen Text, Zeile für Zeile. Implizite Information geht verloren, wenn man nur Prosa verwendet. Es benötigt semantisch zusammengehörende Textblöcke. Idealerweise sollten wir den Inhalt vorbereiten und in semantische Blöcke oder Bereiche segmentieren, um dem LLM einen interpretierbaren Text bereitzustellen.
Größe zählt
LLMs haben Beschränkungen hinsichtlich der Größe von Eingabe- und Ausgabetext. Aktuelle LLMs können nur bis zu einer bestimmten Anzahl (z.B. 4096 Token) von Tokens Text verarbeiten und produzieren (einen Token kann man sich wie eine Wortsilbe vorstellen). Für umfangreiche Dokumente ist daher eine Strategie erforderlich, um den Inhalt in kohärente Segmente zu unterteilen.
LLMs verarbeiten öffentlich zugängliche Dokumente sofort
Die Wirksamkeit einer KI hängt (in den meisten Fällen) von den verfügbaren Trainingsdaten ab, und LLMs sind keine Ausnahme. Sie werden aus öffentlich zugänglichen Quellen wie Websites, Wikipedia, Forschungsarbeiten und Büchern gespeist. Dabei ist für die Lösung einer Aufgabe der Kontext entscheidend. Wenn der Inhalt eines Dokuments und dessen Kontext öffentlich zugänglich sind, kann ein LLM Informationen sofort extrahieren, ohne dass eine zusätzliche Einrichtung erforderlich ist. Vorlaufzeiten für Projekte und das Trainieren eines spezifischen KI-Modells kann man sich somit ersparen.
Funktioniert dies immer?
Betrachten wir die Rechnung, wohl das häufigste Dokument weltweit. Während bestimmte Felder auf Rechnungen standardisiert sind (insbesondere in Europa), können sie firmenspezifische Informationen enthalten, die nicht öffentlich verfügbar sind, was es für ein LLM schwieriger macht, sie zuverlässig zu erfassen. Dazu gehören Informationen wie Bestell-ID-Formate, Tournummern von Logistikunternehmen, Adressen von Konzern-eigenen Unternehmen, interne Produktkataloge, etc. Daher is es entscheidend zwischen öffentlichen Informationen und domänenspezifischem Wissen zu unterscheiden. Wenn ein Anwendungsfall domänenspezifische oder unternehmensbezogene Informationen erfordert, wird das Fine-tuning des Modells oder das Implementieren von Prompts notwendig.
Halluzinationen adressieren
In der KI bezeichnet "Halluzination" Fälle, in denen ein LLM falsche Informationen generiert. Bei der Dokumentenerfassung wandeln wir unstrukturierte Daten in strukturierte und normalisierte Formate um. Das Schöne an strukturierten Daten ist ihre Messbarkeit. Die Zuverlässigkeit eines LLMs bei der Datenerfassung kann statistisch validiert werden. Mit einem umfassenden Benchmark-System können Anbieter von Dokumentenerfassungslösungen die Genauigkeit evaluieren.
Fazit
Obwohl LLMs erhebliche Vorteile bei der Datenerfassung bieten, ist es entscheidend, ihre Grenzen zu erkennen. Die Stärken von LLMs mit domänenspezifischer Expertise und Validierungsmechanismen zu kombinieren, gewährleistet die Genauigkeit und Zuverlässigkeit einer automatisierten Dokumentenerfassung. Ein bedeutender Vorteil bei der Dokumentenerfassung auch mit LLM ist die Möglichkeit, Ausgaben automatisch zu benchmarken. Die Verwendung eines robusten und wiederholbaren Benchmark-Systems, wie es das BLU DELTA-Team verwendet, garantiert vertrauenswürdige Ergebnisse.
BLU DELTA ist ein Produkt für die automatisierte Erfassung von Finanzdokumenten. Partner, aber auch Finanzabteilungen, Kreditorenbuchhalter und Steuerberater unserer Kunden können mit BLU DELTA ihre Mitarbeiter bei der zeitaufwendigen und meist manuellen Erfassung von Dokumenten durch den Einsatz von BLU DELTA KI und Cloud unmittelbar entlasten.
BLU DELTA ist eine Künstliche Intelligenz der Blumatix Intelligence GmbH.

Autor: Christian Weiler ist ehemaliger General Manager eines global agierenden IT Unternehmens mit Sitz in Seattle/US. Seit 2016 ist Christian Weiler vermehrt im Bereich Künstlicher Intelligenz in verschiedensten Rollen tätig und verstärkt seit 2018 das Management Team der Blumatix Intelligence GmbH.
Kontakt: c.weiler@blumatix.com