OCR (Optical Character Recognition -> optische Zeichenerkennung oder auch Texterkennung) ist eine Technologie zur Umwandlung von digitalisierten Bildern oder PDFs, die Text enthalten, in maschinenlesbare Textzeichen. Technisch gesehen bezieht sich OCR auf die Texterkennung, doch in vielen Branchen außerhalb der IT wird OCR allgemein als Dokumentenerfassung verstanden.


Ein OCR-System analysiert die Struktur des Dokuments und unterteilt es in verschiedene Elemente wie Textblöcke, Tabellen und Bilder. Diese Strukturelemente werden weiter in Zeilen, Wörter und schließlich in einzelne Buchstaben zerlegt. Die Buchstaben werden mit einer Datenbank von Musterbildern abgeglichen. Die OCR-Software weist den erkannten Buchstaben standardisierte Codes zu, die in der Datenverarbeitung verwendet werden können.
Durch diese Prozesse ermöglicht OCR die Weiterverarbeitung und Analyse von Texten in verschiedenen Computerprogrammen, was die Effizienz und Genauigkeit bei der Verwaltung und Verarbeitung großer Mengen an Dokumenten erheblich verbessert.
Achtung: Leider gibt es in Diskussionen rund um die Frage "Was ist OCR?" zwischen Fachabteilungen oder auch mit unseren Kunden*innen hier immer wieder Missverständnisse bzgl. der Begrifflichkeit (siehe dazu die Unterscheidung OCR, iOCR und KI).
Inhaltsverzeichnis
- OCR ist die Basis für die Prozess-Automatisierung – dank BLU DELTA KI sogar in der Interpretation der Bedeutung
- Wie funktioniert unsere OCR-Texterkennungssoftware? Was ist der Vorteil der Verknüpfung von OCR & KI?
- Bildqualität ist entscheidend für die Automatisierung mit OCR
- Verschiedene Arten und Anwendungsbereiche von OCR
- BLU DELTA KI zur Texterkennung via Cloud oder OnPremise nutzbar
- Fazit - OCR: Wegbereiter für effiziente Dokumentenverarbeitung
- FAQ: Die wichtigsten Fragen zum Thema OCR
OCR ist die Basis für die Prozess-Automatisierung – dank BLU DELTA KI sogar in der Interpretation der Bedeutung
OCR ist eine Technologie, die die Umwandlung von gescannten Papierdokumenten, PDF-Dateien oder Digitalfotos in bearbeitbare Dokumente für Computer und Software (wie Microsoft Word oder FIBU-Software) ermöglicht. Damit lassen sich selbst Einzelposten extrahieren, wie in diesem Blogbeitrag "Einzelposten erfassen mit OCR" nachzulesen ist.
Die Geschichte der OCR reicht zurück bis in die 1920er-Jahre, als die ersten Ansätze zur maschinellen Texterkennung entwickelt wurden. In den folgenden Jahrzehnten haben sich die Technologien stetig weiterentwickelt, wobei in den 1970er-Jahren die ersten kommerziellen OCR-Systeme/Scanner auf den Markt kamen. Ein bedeutender Fortschritt war die Einführung von maschinellem Lernen und neuronalen Netzen in den 2000er-Jahren, die die Genauigkeit und Effizienz der Texterkennung erheblich verbesserten.
Wenn Sie ein Dokument in Papierform haben – zum Beispiel eine Rechnung, eine Bestellung oder einen Vertrag, den Ihnen jemand als PDF-Anhang geschickt hat – reicht ein Scanner allein nicht aus, um mit den relevanten Informationen aus diesen Dokumenten zu arbeiten. Der Scanner macht nur ein Bild des Dokuments, das aus einer Ansammlung von Bildpunkten besteht. Zur Weiterverarbeitung der Informationen aus gescannten Dokumenten, Digitalbildern oder Bild-PDFs benötigen Sie eine moderne OCR-Software/Anwendung zur Texterkennung. Denn die erkennt in dem jeweiligen Bild sämtliche Zeichen, setzt diese zu Wörtern und Zahlen zusammen und generiert daraus ganze Sätze. Damit erstellt die Software aus einem Bild eine Zeichenkette, einen Text.
Seitdem Deep Learning im OCR-Bereich angewandt wird, hat die Qualität der Texterkennung stark zugenommen und ist auf Augenhöhe mit der menschlichen Erkennungsfähigkeit. Durch den Einsatz von Deep Learning kann die OCR-Technologie nicht nur Zeichen und Wörter präziser erkennen, sondern auch komplexere Layouts und Schriftarten besser verarbeiten. Erfahren Sie hierzu im Detail gerne in unserem OCR vs. DeepOCR-Vergleich mehr.
Nun fehlt aber noch die semantische Bedeutung des Texts und der Zahlen (z. B. "Welche Zahl ist der Bruttogesamtbetrag?"), damit Sie Ihre Prozesse ohne "human in the loop" automatisieren können. Und genau hier kommen wir in Spiel: Wir setzen auf fortschrittliche Algorithmen und künstliche Intelligenz zur Texterkennung, wodurch der Kontext und die Bedeutung der erkannten Zeichen automatisch interpretiert werden. Dies ermöglicht eine vollautomatische Verarbeitung und Analyse der Dokumente, was die Effizienz und Genauigkeit in der Datenverarbeitung erheblich steigert. So lässt sich OCR z. B. optimal für Rechnungen und viele andere Dokumente (siehe auch OCR-Belegerfassung) nutzen.
Wie funktioniert unsere OCR-Texterkennungssoftware? Was ist der Vorteil der Verknüpfung von OCR & KI?

Um zu verstehen, wie eine OCR-Software zur Erkennung aller Zeichen funktioniert, betrachten wir die verschiedenen Schritte, die bei der Texterkennung durchlaufen werden. Wie bereits im Einstieg dieses Textes angeteast, analysiert die OCR-Anwendung zunächst die Struktur des Dokuments. Dafür unterteilt die Technologie die Seite in Textblöcke, Tabellen und Bilder. Diese werden dann in Zeilen gegliedert, die wiederum in Wörter und schließlich in einzelne Buchstaben zerlegt werden. Sobald die Buchstaben identifiziert sind, vergleicht das Programm diese mit einer Reihe von Musterbildern und berechnet die Wahrscheinlichkeit der Übereinstimmung (zum Beispiel könnte ein Zeichen zu 89 % als "A" erkannt werden). Die OCR-Software entscheidet sich dann für das Zeichen, das die höchste Übereinstimmung aufweist.
Ein modernes OCR-System wie unsere Software kann darüber hinaus für mehrere Sprachen konfiguriert werden. Zusätzlich bieten viele OCR-Systeme, darunter auch unsere künstliche Intelligenz zur Texterkennung, eine Wörterbuchunterstützung für unterschiedliche Sprachen an. Diese Unterstützung kann besonders nützlich sein, wenn die OCR für spezielle Domänen, wie zum Beispiel die Buchhaltung, optimiert wird. Die Integration von Fachwörterbüchern und spezifischen Begriffen kann die Genauigkeit der Texterkennung in einem bestimmten Kontext erheblich verbessern.
Ein wesentlicher Fortschritt in der OCR-Texterkennung ist die Integration von Künstlicher Intelligenz (KI), Deep Learning und großen Sprachmodellen (LLM). Denn KI-gestützte Systeme nutzen neuronale Netzwerke, die durch Deep Learning trainiert werden, um Muster und Schriftarten mit einer höheren Präzision zu erkennen. Diese Systeme zur LLM-Datenerfassung sind in der Lage, auch komplexe Layouts und variierende Schriftarten zuverlässig zu verarbeiten und bieten eine signifikant höhere Erkennungsgenauigkeit als traditionelle OCR-Technologien.
Ein weiterer wichtiger Aspekt ist der Unterschied zwischen vortrainierten OCR-Systemen und solchen, die individuell trainiert werden müssen. Vortrainierte OCR-Systeme sind sofort einsatzbereit und bieten eine exzellente Leistung für allgemeine Anwendungen. Sie sind auf eine breite Palette von Schriftarten und Layouts optimiert und können schnell implementiert werden. Individuell trainierte Systeme hingegen erfordern eine spezifische Anpassung an die Bedürfnisse eines Unternehmens, was zusätzliche Zeit und Ressourcen für das Training und die Anpassung benötigt.
Insgesamt zeigt sich, dass die Weiterentwicklung von OCR-Technologien durch den Einsatz von KI, Deep Learning und LLMs die Möglichkeiten der Texterkennung und Dokumentenerfassung erheblich erweitert und verbessert hat. Und genau aus diesem Grund setzen wir auf diese neuen Technologien, um Sie optimal bei der Datenextraktion zu unterstützen!
Bildqualität ist entscheidend für die Automatisierung mit OCR

Die Texterkennung aus einem Bild heraus und die damit einhergehende Umwandlung in ein Dokument dauert nur einige Sekunden. Dadurch erhält man in einem ersten Schritt ohne manuellen Aufwand einen Text und dessen Meta-Informationen rund um Textgröße, Font und Position.
Diese Informationen machen ein Bild nun durchsuchbar und bearbeitbar. Doch für eine ganzheitliche Automatisierung benötigt man selbstverständlich noch die semantische Bedeutung des Texts. Die OCR und die automatisierte Texterkennung sind somit wichtige Grundsteine für die Automatisierung Ihrer Prozesse – aber eben auch noch nicht alles! Denn die Zeichen, Wörter und Zahlen sowie deren Meta-Informationen bilden eine wichtige Datenquelle für darauf aufbauende Algorithmen und KI-Modelle, welche dem Buchstabensalat eine Semantik zuweisen.
Unsere BLU DELTA KI Rechnungserfassung nutzt die Ergebnisse der OCR, um daraus automatisiert und ohne weiteren manuellen Aufwand wertvolle Informationen für die Folgeprozesse (z. B. Kreditorenbuchhaltung) zu extrahieren. Sie erhalten so nicht nur Zeichenketten, Wörter und Zahlen, sondern auch deren Bedeutung.
Wie bereits erwähnt bestimmt die OCR-Software die Wahrscheinlichkeit, wie sehr ein Zeichen einer bestimmten Zahl oder einem bestimmten Buchstaben entspricht. Diese Wahrscheinlichkeit variiert mit der Bildqualität. Unscharfe Bilder, farblich hinterlegter Text oder einfach schlecht gescannte Dokumente können die Qualität stark beeinflussen. Wir sehen in unseren regelmäßigen BLU DELTA Benchmarks (Qualitätsmessung bei KI), dass die Foto- und Scanqualität für die nachfolgenden Prozesse entscheidend ist.
Eine "8" wird schnell zu einer "6" oder zu einem "B". Ein "gekippter" Buchstabe hat bei uns jedoch keine Auswirkungen auf die Automatisierung. Moderne NLP-Ansätze (Natural Language Processing), wie wir sie auch bei BLU DELTA verwenden, reduzieren solche Einzelfehler.
Bis zu 30 % höhere Automatisierungsrate
Hervorgerufen durch schlechte Scan- und Bildqualität sehen wir bei unseren Kunden Differenzen von bis zu 30 % bei den Automatisierungsraten in der Dokumentenerfassung. Man unterscheidet bei der Eingangsqualität zwischen Digitalfoto, Scan und PDF-Text. Diese Unterschiede sind auch ein Grund, warum wir bei BLU DELTA für die Rechnungserfassung eine Vorhersage der Automatisierungsrate anbieten.
Digitalfoto und OCR
In der Regel weisen Bilder, die mit mobilen Endgeräten aufgenommen wurden, folgende Probleme auf:
- Schatten
- Ungleichmäßige Ausleuchtung
- Falsche Perspektive
- Zusätzliche Bereiche außerhalb der Seitengrenzen
Eine OCR-Software kann diese Probleme bis zu einem bestimmten Grad korrigieren. Trotzdem bilden Digitalfotos durch die oben genannten Punkte die größte Herausforderung für die Automatisierung. Sogenannte CamScanner oder ähnliche mobile OCR-Scanner und/oder Bild-Optimierungen können hier die Qualität vorab entsprechend verbessern.
Scan und OCR
Professionelle Scanner bieten bereits eine gute Basis für die automatisierte Verarbeitung und Erfassung von Dokumenten. Wenn möglich, dann scannen Sie Ihre Dokumente in Schwarz/Weiß (somit ist eine verlustfreie Komprimierung möglich) und mit mind. 300dpi. Kleine Schriften bis zu 9pt können so noch gut erkannt werden.
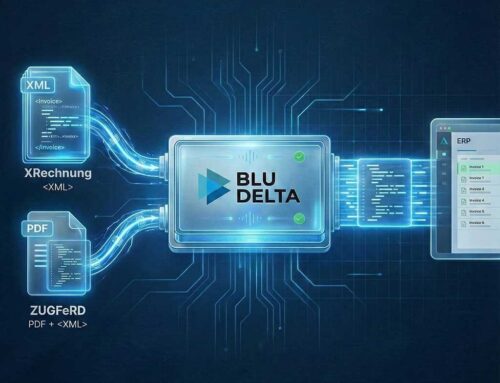
PDF-Text und OCR
PDF-Text liefert die besten Ergebnisse. Hier entfällt meist der eigentliche OCR-Prozess. Das PDF-Dokument enthält bereits die Zeichen in digitaler Form und der Folgeprozess muss "nur" noch die Semantik erkennen. Dokumente im reinen PDF-Text Format erreichen bei der BLU DELTA KI Gesamterkennungsraten von mehr als 90 %. Wenn möglich sollten Sie daher bei Ihren Dokumentquellen darauf achten, dass Sie unstrukturierte oder semistrukturierte Dokumente als PDF-Text erhalten.
Allerdings sind auch PDF-Text-Dokumente oftmals mit Bildern angereichert, in denen Text Informationen enthalten sind. Somit relativiert sich in diesem Fall der Vorteil.
Verschiedene Arten und Anwendungsbereiche von OCR

Optische Zeichenerkennung ist eine vielseitige Technologie, die in verschiedenen Formen und für eine Vielzahl von Anwendungsbereichen eingesetzt werden kann. Es gibt hauptsächlich zwei Arten von OCR-Systemen: Texterkennung und Handschriftenerkennung (ICR). Die Texterkennung wird verwendet, um gedruckten Text aus digitalen Bildern, Scans oder PDFs zu extrahieren, während die Erkennung der Handschrift darauf abzielt, handgeschriebene Notizen oder Dokumente in maschinenlesbaren Text umzuwandeln.
Speziell im Bereich (Kreditoren-)Buchhaltung wird der Begriff OCR oftmals mit der Erfassung von Informationen von Rechnungen gleichgesetzt. Technisch gesehen ist dies jedoch ein getrennter Prozess. Die BLU DELTA KI enthält eine Komponente für die Texterkennung und darauf aufbauend KI-Modelle, die die semantischen Zusammenhänge erfassen.
OCR findet Anwendung in zahlreichen Branchen:
- In der Buchhaltung wird OCR verwendet, um Rechnungen und Belege zu digitalisieren und zu verarbeiten.
- Im Gesundheitswesen ermöglicht OCR die schnelle und genaue Erfassung von Patientendaten und medizinischen Aufzeichnungen.
- In der Logistik hilft OCR bei der Verwaltung und Verfolgung von Lieferdokumenten und Sendungsverfolgung.
- Versicherungen nutzen OCR zur Automatisierung der Schadenbearbeitung.
- Im Finanz- und Bankwesen ermöglicht OCR die effiziente Verarbeitung von Transaktionen und Dokumenten.
- Auch im Immobilienbereich wird OCR verwendet, um Dokumente wie Mietverträge und Grundstücksurkunden zu digitalisieren.
BLU DELTA KI zur Texterkennung via Cloud oder OnPremise nutzbar

Die Wahl zwischen OnPremise und Cloud basierten OCR-Lösungen hängt oft von den spezifischen Anforderungen der Branche und den Datensicherheitsbedürfnissen ab. Bei unserer Software ist beides möglich. Entscheiden Sie sich für die OnPremise-Version, wird diese lokal auf den Servern Ihres Unternehmens installiert und bietet eine hohe Kontrolle über Daten und Prozesse, ist jedoch mit etwas höheren Anfangskosten und mehr Wartungsaufwand verbunden. Wählen Sie die Lösung per Cloud, ermöglicht diese eine flexible und skalierbare Nutzung.
Zum Thema Datensicherheit sei noch gesagt: Im Kontext von Informationssicherheitsmanagementsystemen (ISMS) und der Datenschutz-Grundverordnung (GDPR) müssen OCR-Systeme so konfiguriert sein, dass sie den geltenden Datenschutz- und Sicherheitsanforderungen entsprechen, um die Vertraulichkeit und Integrität der verarbeiteten Daten zu gewährleisten. Diese Anforderung erfüllen selbstverständlich unsere beiden Versionen.
Fazit - OCR: Wegbereiter für effiziente Dokumentenverarbeitung
Optische Zeichenerkennung (OCR) ist eine leistungsstarke Technologie zur Umwandlung gescannter Dokumente, Bilder und PDFs in maschinenlesbare Textdaten. Durch die Analyse und Interpretation von Textstrukturen ermöglicht OCR in Verbindung mit Künstlicher Intelligenz eine effiziente Automatisierung und Verarbeitung von Informationen in verschiedenen Branchen wie Buchhaltung, Gesundheitswesen, Logistik, Versicherung und Finanzwesen. Die kontinuierliche Weiterentwicklung von Technologien wie Deep Learning hat die Präzision und Flexibilität von OCR-Systemen erheblich verbessert, indem sie sowohl gedruckte als auch handgeschriebene Texte zuverlässig erkennen. Während OnPremise und Cloud basierte OCR-Lösungen unterschiedliche Vorteile und Anforderungen bieten, hängt die Wahl der geeigneten Lösung von den spezifischen Bedürfnissen und Sicherheitsanforderungen der jeweiligen Branche ab. Insgesamt stellt OCR eine wesentliche Grundlage für die digitale Transformation und Effizienzsteigerung in der Dokumentenverarbeitung dar.
BLU DELTA ist ein Produkt für die automatisierte Erfassung von Finanzdokumenten. Partner, aber auch Finanzabteilungen, Kreditorenbuchhalter und Steuerberater unserer Kunden können mit BLU DELTA ihre Mitarbeiter bei der zeitaufwendigen und meist manuellen Erfassung von Dokumenten durch den Einsatz von BLU DELTA KI und Cloud unmittelbar entlasten.
BLU DELTA ist eine Künstliche Intelligenz der Blumatix Intelligence GmbH.

Autor: Christian Weiler ist ehemaliger General Manager eines global agierenden IT Unternehmens mit Sitz in Seattle/US. Seit 2016 ist Christian Weiler vermehrt im Bereich Künstlicher Intelligenz in verschiedensten Rollen tätig und verstärkt seit 2018 das Management Team der Blumatix Intelligence GmbH.
Kontakt: c.weiler@blumatix.com