Im ersten Teil vergleichen wir traditionelle OCR-Technologien mit DeepOCR. Im zweiten Abschnitt gehen wir im Detail auf die Performance von drei bekannten DeepOCR Open-Source Alternativen ein.
In der IT-Küche brodelt der KI-Eintopf – neben Computer Vision vor allem auch im Bereich OCR-Texterkennung. Viele etablierte Softwareunternehmen kämpfen damit, ihre veraltete Software zumindest in Marketing-Broschüren auf neueste KI Standards zu heben.
Klassische Software-Algorithmen wurden bis 2015 und teilweise noch bis heute mit wenig Fortschritt im Bereich optische Zeichenerkennung optimiert und ausgereizt. Seit ca. 2015 öffnet hier KI neue Möglichkeiten, die aktuell am Markt auch schon an vielen Stellen genutzt werden. Speziell unter dem Begriff DeepOCR tummeln sich neue Produkte am Markt, die eine neue Qualität versprechen und die zum Teil sogar quelloffen verfügbar sind.
WICHTIG: Hier geht es um die reine Texterkennung auf Zeichen und evtl. Wortebene. Der Begriff wird aus finanztechnischer Sicht aufgrund der Historie etwas ausgereizt und firmiert fälschlicher Weise auch oftmals unter Beleg- oder Rechnungserfassung. Um hier Klarheit zu schaffen, haben wir zu dem Thema OCR, iOCR und KI einen eigenen Artikel verfasst. Außerdem beantworten wir Ihnen gerne auch die Frage „Was ist OCR?“ in einem weiteren Beitrag.
Als Anbieter einer iOCR (BLU DELTA KI) müssen wir den Markt im Auge behalten und möchten hiermit unsere Ergebnisse zur Verfügung stellen.

Ziel des Tests der OCR-Texterkennung
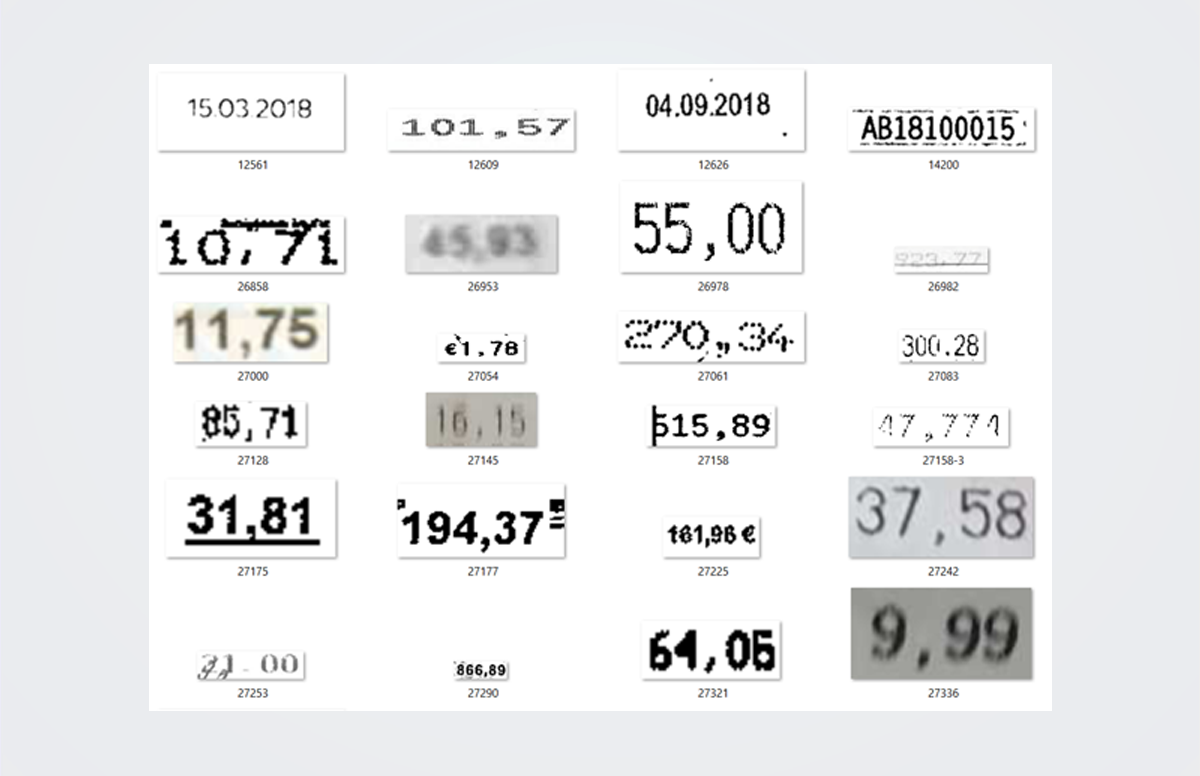
Aus diesem Grund haben wir im Mai 2022 eine kleine aber feine Auswahl an Texterkennungs-Tools miteinander verglichen. Das Ziel war dabei eine Indikation zu bekommen, ob sich am Markt im Bereich Deep Learning aus qualitativer Seite etwas bewegt. Dabei wurde ein Benchmark von Ziffern und Zahlen angelegt: 89 Zahlen bestehend aus 570 Zeichen im Benchmark wurden dabei als Ground Truth verwendet.
Hinweis: Zahlen wurden verwendet, da man diese im Folgeprozess eines iOCR nicht oder nur selten korrigieren kann. Kippt evtl. der eine oder andere Buchstabe bei der Erkennung, so kann man über „Ähnlichkeiten“ wieder auf das korrekte Wort Rückschlüsse ziehen (z.B. auch über NLP Modelle), was bei Zahlen nicht möglich ist.
Die Messung (Benchmark Setup)
Im Benchmark vertreten waren ca. 66% Zahlen aus Dokumenten mit guter und ca. 33% mit schlechter Bildqualität. Alle Daten stammten von Original-Rechnungen und Kassenbelegen wie sie am Markt immer wieder vorkommen. Es war kein rein zufällig gezogenes Sample sondern hatte im Vergleich zu üblichen Rechnungen und Kassabelegen einen Bias in Richtung schlechter Bildqualität. Die Produkte wurden off-the-shelf getestet und es wurde kein Training vorgenommen.
Die Messungen erfolgten über 2 Indikatoren:
- Exact Match: Die Zahl muss exakt mit der Ground Truth übereinstimmen.
- Levenshtein Distance: Wie ähnlich sind sich die erkannten Werte; dient als Messung für Qualität der einzelnen Zeichen
Wir möchten darauf hinweisen, dass es viele Kriterien gibt, die eine Beurteilung begründen. In unserem Fall war es ausschließlich die Erkennungsrate bei Zahlen bzw. Ziffern.
Die Ergebnisse:
|
Tool |
Exakt |
Levenshtein |
|
92% |
95,70% |
|
|
64% |
92,26% |
|
|
71% |
86,47% |
|
|
62% |
82% |
|
|
57% |
73% |
|
|
50% |
74% |
|
|
42% |
69% |
Unser Fazit zur OCR-Texterkennung
Dass Google in den letzten Jahren durch neueste KI-Architekturen zum qualitativen Marktführer der Online-OCR aufgestiegen ist, ist kein Geheimnis. Aber für den Use Case Geschäftsdokumente und Scan scheint ein echter OpenSource-Herausforderer aus Asien zu entstehen - PaddleOCR.
Auffällig ist, dass beide (Google und Paddle) DeepLearning (DeepOCR) einsetzen und bei schlechter Bildqualität augenscheinlich viel besser waren als die Konkurrenz. Google als auch Paddle dürften durch DeepLearning und Daten hier in sehr kurzer Zeit viel erreicht haben. Paddle kann man dazu auch noch mit eigenen Daten trainieren und entsprechend verbessern. Es ist anzunehmen, dass Paddle mit Training eine ähnliche Performance wie Google erreichen kann.
Weitere Anmerkungen zum Test:
- MMOCR wäre ebenfalls ein Open-Source-Kandidat gewesen, jedoch konnte hier unser Format nicht gelesen werden.
- PaddleOCR hatte einen Bug, den wir vorher korrigiert haben, bevor wir die Ergebnisse nutzen konnten (1 Leerzeichen nach jedem Komma).
Die Texterkennung hat im Bereich intelligentes OCR durch NLP etwas an Bedeutung verloren, stellt aber die Basis für jede KI zur Erkennung der Semantik im Folgeprozess dar. Eine nachgeschaltete KI-Architektur nutzt dabei die erkannten Zeichen, um diese auf Wörter, Sätze und Bedeutung abzubilden. Ein transparentes Feedback aus der Oberfläche des Kunden zurück zum KI-System führt dabei zu einem bleibenden Lerneffekt (siehe auch BLU DELTA Shared Intelligence Konzept).
Update!
DeepOCR: PaddleOCR, MMOCR und EasyOCR im Vergleich
Im ersten Teil des Artikels haben wir traditionelle OCR-Technologien mit DeepOCR verglichen. In diesem Abschnitt wollen wir nun im Detail die Performance von drei bekannten DeepOCR Open Souce Alternativen etwas genauer unter die Lupe nehmen.
Die Eckdaten der Kandidaten
- Paddle OCR v0.6.1
- License: Apache License 2.0
- Supported Languages (pre-trained): 80(+)
- URL: https://github.com/PaddlePaddle/PaddleOCR
- MM OCR v2.5.0.3
- License: Apache License 2.0
- Supported Languages (pre-trained): Chinese, English
- URL: https://github.com/open-mmlab/mmocr
- Easy OCR v1.5.0
- License: Apache License 2.0
- Supported Languages (pre-trained): 80(+)
- URL: https://github.com/JaidedAI/EasyOCR
Der Benchmark
Um ein repräsentatives Sample zu bekommen, haben wir aus unserem Dokumentenfundus 400 reale Rechnungen zufällig ausgewählt und daraus alle verfügbaren Text Labels mit ihren Bounding Boxen extrahiert. Die Rechnungsdokumente haben wir stark „geblurrt“, sodass ausgenommen von der Label Bounding Box nichts mehr lesbar war. Somit erhielten wir eine Groundtruth mit 2326 Bilder mit je einem Klartext Label.

Abb.: Beispiel Dokument mit Label Dokumentendatum
Das DeepOCR Ergebnis:
Nach unserem ersten Test mit Ziffern und Zahlen – wo Paddle mit seiner Accuracy herausragend war – hätten wir uns hier auch Paddle als Sieger erwartet. Jedoch hat Paddle speziell bei Sonderzeichen, Punkten und Kommas Schwächen gezeigt. Überraschend war auch, dass Paddle mit GPU relative wenig schneller wurde.
MMOCR, welches neben Chinesisch nur Englisch untesrtützt, muss man eigentlich außer Konkurrenz werten. Unser Becnhmark Set bestand vorrangig aus europäischen Rechnungen und hier mit einem Schwerpunkt Deutsch. Zusätzlich erkannte MMOCR Großbuchstaben nicht out-of-the-box.
Easy OCR hat uns positiv überrascht und geht für unseren Use Case als klarer Gewinner hervor so lange man eine GPU bei der Inference einsetzen kann. Der große Vorteil ist natürlich, dass man diese OCR noch entsprechend für eine verbesserte Text Erkennung und Texterfassung trainieren kann.
Will man sich den Trainingsaufwand ersparen, dann empfiehlt sich EasyOCR mit GPU.

BLU DELTA ist ein Produkt für die automatisierte Erfassung von Finanzdokumenten. Partner, aber auch Finanzabteilungen, Kreditorenbuchhalter und Steuerberater unserer Kunden können mit BLU DELTA ihre Mitarbeiter bei der zeitaufwendigen und meist manuellen Erfassung von Dokumenten durch den Einsatz von BLU DELTA KI und Cloud unmittelbar entlasten.
BLU DELTA ist eine Künstliche Intelligenz der Blumatix Intelligence GmbH.

Autor: Christian Weiler ist ehemaliger General Manager eines global agierenden IT Unternehmens mit Sitz in Seattle/US. Seit 2016 ist Christian Weiler vermehrt im Bereich Künstlicher Intelligenz in verschiedensten Rollen tätig und verstärkt seit 2018 das Management Team der Blumatix Intelligence GmbH.
Kontakt: c.weiler@blumatix.com